MiniTool PDF Editor is a multifunctional PDF editing utility. By using it, you can extract images from PDF, extract pages from PDF, copy image from PDF, merge image to PDF, convert a file to PDF, etc. With multiple functions, it can be used as an image converter, PDF markup software, PDF translator, PDF annotator, and so on.
MiniTool PDF EditorClick to Download100%Clean & Safe
Reasons for Extracting Metadata from PDF
Metadata is a crucial part of any file, especially PDFs. PDF metadata is as important as the content of the PDF. Since the PDF format gradually becomes the standard of multiple domains, its importance will level up in the future.
Then you may want to extract metadata from PDF files. Besides, there are some other reasons for extracting metadata from PDFs.
- Sort and find files more easily
- Search for data in files faster
- Make sure files follow the right rules
- Keep private information safe by checking who sees it
- Make it easy to use files with other programs
- Verify files for correct information and data accuracy
- Offer you good ideas for making decisions
Related articles:
How to Remove Metadata from PDF? Try These Ways
Add/Edit PDF Metadata Online and Offline [Step-by-Step Guide]
Extract Metadata from PDF via Chrome Extensions
Chrome extensions like Extract Metadata from PDF enable you to extract metadata from PDFs. You can add it to the Chrome browser and then use it to extract metadata from PDF files. How to do that? Here are the steps for doing that.
Step 1: Navigate to this page and then click the Add to Chrome button.

Step 2: In the pop-up window, click Add extension to confirm the operation. Then the extension will be added to your browser.
Step 3: Click on the icon of the Extract Metadata from PDF extension at the upper right corner of the browser to open it. Then click the Extract Metadata from PDF button to continue.
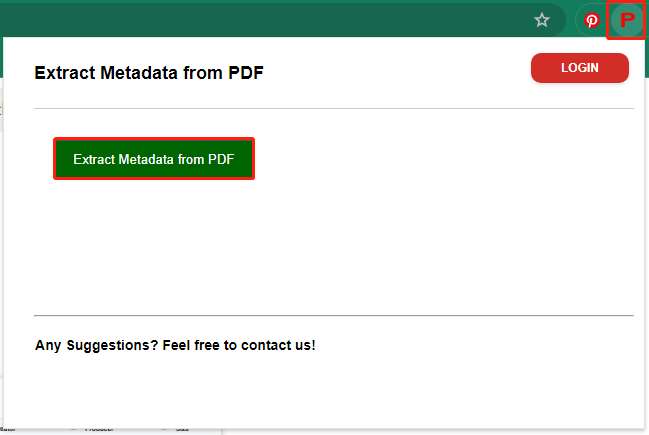
Step 4: In the next window, click Choose Files to find and open the target PDF. Alternatively, you can also drag and drop the PDF into the page.

Step 5: After the PDF file is uploaded, then the metadata will be extracted automatically.
Extract Metadata from PDF via Python
If you are an expert at using Python, you can extract metadata from PDF via it. Before starting the process, download and install pyPDF2 package on your computer. Then follow the steps below to complete the extraction operation.
Step 1: Launch Python on your PC.
Step 2: Open the PDF and extract metadata by writing a Python script using pyPDF2.
import PyPDF2
# Open the PDF file
pdf_file = open('your_pdf_file.pdf', 'rb')
# Create a PDF reader object
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
# Access metadata
metadata = pdf_reader.getDocumentInfo()
# Extract metadata
title = metadata.get('/Title', 'No Title')
author = metadata.get('/Author', 'No Author')
subject = metadata.get('/Subject', 'No Subject')
keywords = metadata.get('/Keywords', 'No Keywords')
creator = metadata.get('/Creator', 'No Creator')
producer = metadata.get('/Producer', 'No Producer')
created_date = metadata.get('/CreationDate', 'No Creation Date')
modified_date = metadata.get('/ModDate', 'No Modification Date')
# Print or save metadata
print(f'Title: {title}')
print(f'Author: {author}')
print(f'Subject: {subject}')
print(f'Keywords: {keywords}')
print(f'Creator: {creator}')
print(f'Producer: {producer}')
print(f'Creation Date: {created_date}')
print(f'Modification Date: {modified_date}')
# Close the PDF file
pdf_file.close()
Step 3: Execute the script. Then it will display or save the metadata as you have programmed it.

Extract Metadata from PDF via Third-Party Software
In addition to the above methods, professional PDF metadata extractors can help you extract metadata from PDF files too. For instance, you can use tools like Adobe Acrobat, PDF.co PDF Info Reader, and GroupDocs.Metadata to complete the operation.
How to extract metadata from PDF via Adobe Acrobat? Here’s a full guide for you.
Step 1: Launch Adobe Acrobat and open the PDF file from which you want to extract metadata.
Step 2: Click the file and choose Properties.
Step 3: In the Properties box, switch to the Description tab. Then you will view metadata fields like Title, Author, Subject, and Keywords.
Step 4: To extract any of this information, choose and copy the text.
Step 5: Paste the copied metadata into a text document or note app to save it for future reference.
Conclusion
Several available methods to extract metadata from PDFs have been provided to you. Now, it’s your turn to make a choice. Select a way from the post to extract PDF metadata.